
Data Science - Individual Assignment 1 Week 2
Individual Assignment Data Science Python Language
| Topic | Introduction to Python Language |
|---|---|
| Sub Topic | Control Flow and Looping |
| Reference | LN |
Below is the data of employees of a private company who commute to the office using either private or public transportation.
| No. | Gender | Employee Age | Salary | Transportation |
|---|---|---|---|---|
| 1 | Male | 20 | 8,000,000 | Private Vehicle |
| 2 | Male | 35 | 14,000,000 | Public Transport |
| 3 | Female | 26 | 10,000,000 | Public Transport |
| 4 | Female | 27 | 12,000,000 | Private Vehicle |
| 5 | Male | 21 | 9,000,000 | Private Vehicle |
| 6 | Male | 22 | 11,000,000 | Private Vehicle |
| 7 | Female | 32 | 15,000,000 | Public Transport |
| 8 | Female | 26 | 8,000,000 | Public Transport |
| 9 | Male | 25 | 9,000,000 | Public Transport |
| 10 | Female | 20 | 10,000,000 | Private Vehicle |
Based on the data in the table, create a Python program and provide a screenshot of the output.
-
Use control flow to determine job positions based on salary:
-
Salary = 8 million – 9 million, position = Officer
-
Salary = 10 million – 11 million, position = Supervisor
-
Salary = 12 million – 14 million, position = Assistant Manager
-
Salary ≥ 15 million, position = Manager
-
-
Use looping to display the highest and lowest salaries.
Solution
-
Control Flow to Determine Positions
# Creating a function to determine positions based on salary
def assign_position(salary):
if 8000000 <= salary <= 9000000:
return 'Officer'
elif 10000000 <= salary <= 11000000:
return 'Supervisor'
elif 12000000 <= salary <= 14000000:
return 'Assistant Manager'
elif salary >= 15000000:
return 'Manager'
else:
return 'Unknown'
# Adding the Position column to each data row
for row in data:
row.append(assign_position(row[3]))Explanation:
-
The assign_position function takes salary as a parameter and returns positions based on the given rules.
-
In the for loop, this function is called for each data row, and the result is added to the row as a new column named "Position."
-
-
Looping to Display Highest and Lowest Salaries:
# Determining column widths based on the longest value in each column
column_widths = [len(str(header[i])) for i in range(len(header))]
for row in data:
for i in range(len(row)):
column_widths[i] = max(column_widths[i], len(str(row[i])))
# Displaying the table header
print("\t|\t".join(f"{header[i]:<{column_widths[i]}}" for i in range(len(header))))
print("--" * (sum(column_widths) + len(column_widths) - 1))
# Displaying employee data with positions
for row in data:
row.append(assign_position(row[3])) # Adding the Position column to each data row
print("\t|\t".join(f"{str(row[i]):<{column_widths[i]}}" for i in range(len(header))))Explanation:
-
In the first loop, the maximum length of each column is calculated to format the table output later.
-
The table output is created to ensure each column has the appropriate width.
-
Employee data, including the newly determined positions, are printed in a table format with the previously calculated column widths.
-
Full Source Code
# Employee data
data = [
[1, 'Male', 20, 8000000, 'Private Vehicle'],
[2, 'Male', 35, 14000000, 'Public Transport'],
[3, 'Female', 26, 10000000, 'Public Transport'],
[4, 'Female', 27, 12000000, 'Private Vehicle'],
[5, 'Male', 21, 9000000, 'Private Vehicle'],
[6, 'Male', 22, 11000000, 'Private Vehicle'],
[7, 'Female', 32, 15000000, 'Public Transport'],
[8, 'Female', 26, 8000000, 'Public Transport'],
[9, 'Male', 25, 9000000, 'Public Transport'],
[10, 'Female', 20, 10000000, 'Private Vehicle']
]
# Adding the Position column based on Salary
def assign_position(salary):
if 8000000 <= salary <= 9000000:
return 'Officer'
elif 10000000 <= salary <= 11000000:
return 'Supervisor'
elif 12000000 <= salary <= 14000000:
return 'Assistant Manager'
elif salary >= 15000000:
return 'Manager'
else:
return 'Unknown'
# Creating a header for the table
header = ["No.", "Gender", "Employee Age", "Salary", "Transportation", "Position"]
# Calculating column widths based on the longest value in each column
column_widths = [len(str(header[i])) for i in range(len(header))]
for row in data:
for i in range(len(row)):
column_widths[i] = max(column_widths[i], len(str(row[i])))
# Displaying the table header
print("\t|\t".join(f"{header[i]:<{column_widths[i]}}" for i in range(len(header))))
print("--" * (sum(column_widths) + len(column_widths) - 1))
# Displaying employee data with positions
for row in data:
row.append(assign_position(row[3])) # Adding the Position column to each data row
print("\t|\t".join(f"{str(row[i]):<{column_widths[i]}}" for i in range(len(header))))
# Sorting data based on Salary
data.sort(key=lambda x: x[3])
# Displaying the lowest and highest salaries after sorting
print("\nLowest Salary:", data[0][3])
print("Highest Salary:", data[-1][3])
Live code:
Simulation
Here is a simulation of the
output result:
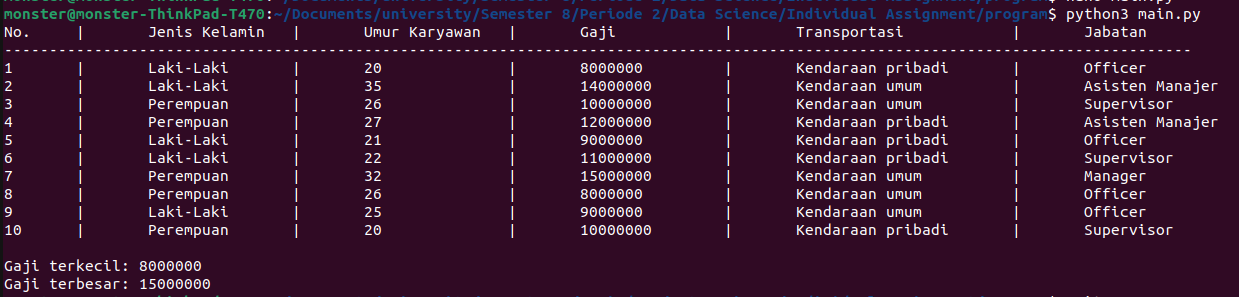
Live simulation:
Correlation with Data Science:
-
Control Flow (Decision Making): In the first step, control flow is used to make decisions based on salary values, which is a common aspect in data processing and analysis.
-
Looping (Iterative Process): The second step uses looping to display data while ensuring a neat table format. This reflects the iterative principle in data science, where we often need to iterate processes for data analysis or manipulation.
-
Data Manipulation: Adding the "Position" column to each row is an example of data manipulation, which is an essential part of data science for making data more informative and ready for further analysis.
-
Data Presentation: The neat table output format aids in data presentation, which is a critical aspect of communicating data analysis results to other stakeholders within the organization.
Conclusion
This article demonstrates how Python can be used to analyze employee data and determine positions based on salary, as well as display information on the smallest and largest salaries. Through the use of control flow and looping, the process is illustrated clearly.
References
Grus, J. (2019). Data science from scratch: first principles with python. O'Reilly Media.
Cuadrado-Gallego, J. J., & Demchenko, Y. (2023). Introduction to data science and data analytics. In Springer eBooks (pp. 1–44).
Share this post
Author

Dikhi MartinSoftware Engineer